Justin Rodermond, Director of Platform Engineering, and Luis Aguilar, Staff Platform Engineer, join the Stellate blog to write about Skillshare's journey to GraphQL.
In 2018, the REST API we originally built in our PHP monolith for our mobile apps had become a performance and maintainability bottleneck. Opening up certain screens in the apps would kick off dozens of requests, taking 3-5s each and loading kilobytes of data.
First steps with GraphQL and Node
Luis joined the team in March 2018 as we had started thinking about moving parts of our application to Node, and he suggested we try GraphQL. Using it would allow our clients to fetch the exact data they need with a single request, which sounded like an ideal solution for the bottleneck issue, as well as an empowering step forward for our clients in terms of maintainability.
There was a strong appetite from the engineering team for full-stack JavaScript to make it easier for individual contributors to work across the entire stack. We had also begun making the shift toward microservices and were investing heavily in a continuous delivery culture. We believe that allowing teams to iterate and deploy quickly is a critical component to creating great teams and creating great software.
So, we created the first prototype of our GraphQL API as a Node microservice.
We focused on reimplementing the parts of the API that fed the home screen of the iOS and Android apps, as they used an isolated piece of our data set: content rows of class collections. Once we completed that work, we ran an A/B test: one variant using the legacy PHP REST API, and one variant using the new Node GraphQL API.
A/B testing GraphQL vs. REST
Shortly after running that A/B test in production, it became clear that the experiment was a resounding success: the average response time dropped to about 100 - 200ms. That was about a 15x performance gain. The new API was not only much faster, but also the clients loaded much less data.
We became confident enough to plan to migrate our entire API to GraphQL and Node.
Rewrite difficulties
We started reimplementing core parts of our PHP monolith, such as the "User" model, in Node and GraphQL. However, the further we went down this route, the more we realized that such an aggressive rewrite entailed a large set of problems. For example, we had to deal with syncing the state of this core business logic between the two systems, running into a problem of multiple sources of truth --- a nightmare to debug and maintain in production.
That's when an idea struck us: what if we added GraphQL to the PHP monolith as well?
If the PHP monolith exposed a GraphQL API for all of the core models (like "Class" and "User") and we could combine that with the schema of the Node service, we wouldn't have to rewrite our entire core business logic at all. On top of that, our backend could shift towards microservices on a team-by-team basis without our clients having to be aware of the change.
Serendipitously, around that time the Apollo Team announced their newest solution to a consolidated GraphQL architecture, Apollo Federation.
Apollo Federation to the rescue
In a similar fashion to how an API gateway server combines multiple REST APIs, Apollo Federation allows one to declaratively combine multiple GraphQL "subgraphs" into a single "supergraph" which is exposed to the outside world. Essentially, our Node service could "extend" a GraphQL schema exposed from the PHP monolith and reuse all the business logic that already exists there.
However, Apollo Federation was in nascent stages and platform support was limited. While support has expanded since it is still only available for Node and very few other platforms. Our service strategy depended on this, so we went to work implementing Apollo Federation in PHP, a project that we hope to open source at some point.
Looking forward
A few months later, we ran our very first federated query combining data from our PHP and Node services. It was a major milestone. Our clients were now truly agnostic to what was going on beyond the supergraph. We have since seamlessly migrated schema elements (types, fields, etc.) from one service to the other. It's worth mentioning that, at the time of writing, we have a total of six services all exposing their own subgraph.
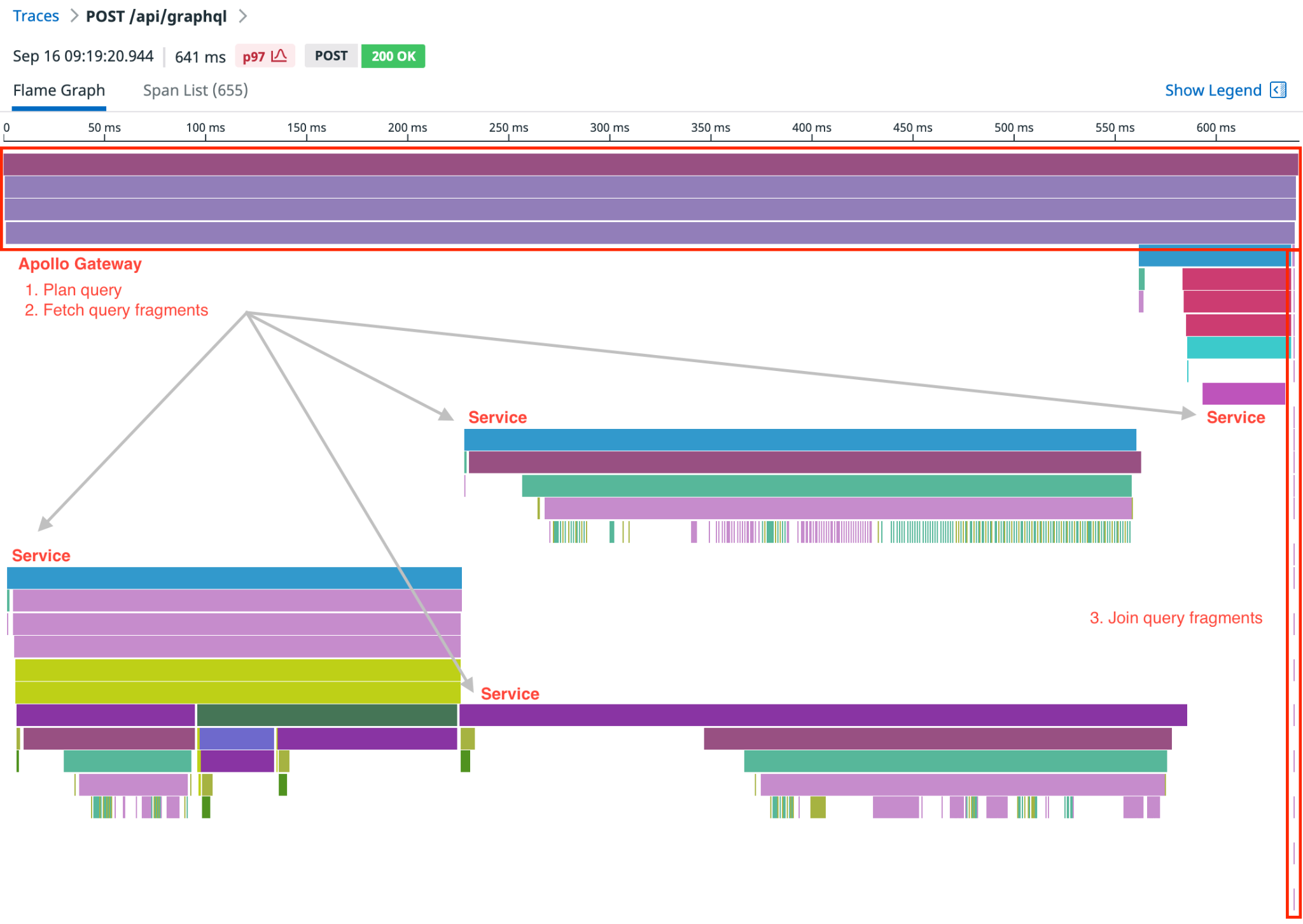
The ability for us to combine a modern Node stack with our modernized PHP stack means that we can quickly implement backend functionality while giving our clients flexibility and data access through GraphQL. While there are still technical hurdles to cross in the future, we are confident that these technology choices have allowed us to embrace our underlying strategic architecture, which is building great teams.
If working on interesting technical problems with a modern stack at a large scale sounds interesting to you, Skillshare is hiring Staff Backend Engineers right now!